Towards Optimized Microservices Performance & Sustainability via Istio, Kepler and Smart Scheduling
Guest post as part of the cloud native sustainability week
KubeCon + CloudNativeCon + Open Source Summit China 2023 took place in Shanghai from September 26 to 28, drawing significant attention to sustainability-related topics from the attendees. One notable talk at the event discussed this important theme. Below, we recap this talk about environmental sustainability at the conference.
Problem, Challenges, and Solutions
In the landscape of microservices orchestration, challenges arise that demand precise solutions. The inherent distributed nature of microservices leads to increased resource consumption and higher infrastructure costs. Efficient resource allocation while ensuring scalability is a pressing concern. Service interactions introduce latency, affecting overall performance. Latency and Service Interactions present complex problems, demanding optimization of communication pathways within microservices applications. Furthermore, the rapid proliferation of microservices raises environmental concerns, specifically regarding energy consumption and carbon footprint. Striking a balance between performance and environmental responsibility is crucial.
To address these challenges, several key solutions come into play. Microservices form the foundational framework, enhancing scalability and flexibility within applications. Istio, an open-source service mesh platform, ensures seamless communication and mitigates latency by orchestrating traffic management and observability. Kepler probes CPU performance counters and kernel tracepoints, shedding light on power dynamics and guiding architects toward energy-efficient practices. Kubernetes Scheduling allocates resources, ensuring optimal utilization and preventing wastage. Artificial Intelligence (AI) integrates seamlessly with Istio, Kepler, and smart scheduling, enhancing microservices management through intelligent decision-making, real-time monitoring, and adaptive resource allocation.
These tools act as strategic enablers, transforming challenges into practical solutions, orchestrating a future where microservices resonate with the tunes of innovation, efficiency, and environmental consciousness.
Istio and Microservice
Istio stands as a transformative solution, seamlessly extending Kubernetes capabilities to create a programmable and application-aware network. By harnessing the robust Envoy service proxy, Istio orchestrates a harmonious integration between Kubernetes and traditional workloads. This integration brings forth standardized and universal tools for traffic management, telemetry, and security, elevating the intricacies of complex deployments.
One of Istio’s notable strengths lies in its ability to generate comprehensive service metrics, offering deep insights into microservices interactions. These metrics cover crucial aspects such as latency, traffic patterns, errors, and service saturation, providing architects with a clear and real-time view of their microservices ecosystem.
Specifically tailored for HTTP, HTTP/2, and GRPC traffic, Istio’s metrics offer a granular understanding of the communication dynamics within microservices. By monitoring these key parameters, Istio empowers architects and developers to optimize their applications effectively, ensuring seamless performance and reliability in the ever-evolving landscape of modern software architectures.
Our main focus is on the hotelReservation end-to-end service, an essential part of the DeathStarBench open-source benchmark suite designed for cloud microservices. Developed in a straightforward manner using modern cloud-native techniques, this service simulates a typical microservice workload, specifically a hotel booking system. It’s written in the efficient Go programming language (golang) and utilizes gRPC-go for communication between microservices. This service is instrumental in our study, allowing us to explore different resource scheduling scenarios in a practical and accessible way, making it an ideal choice for our analysis.
Kepler and Power Modeling
Kepler, known as the “Kubernetes-based Efficient Power Level Exporter,” operates by utilizing eBPF technology to examine CPU performance counters and Linux kernel tracepoints. These gathered data, including information from BPF context switch events and sysfs, are inputted into machine learning models. This process enables us to estimate the power consumption of Kubernetes Pods accurately. From its inception, Kepler adheres to three fundamental principles: it is designed to be ubiquitous, capable of running on various platforms like bare-metal or virtual machines, supporting different architectures such as x86, ARM, or S390. Additionally, it is lightweight, ensuring a small footprint and low overhead, and it is grounded in scientific research, relying on well-studied principles.
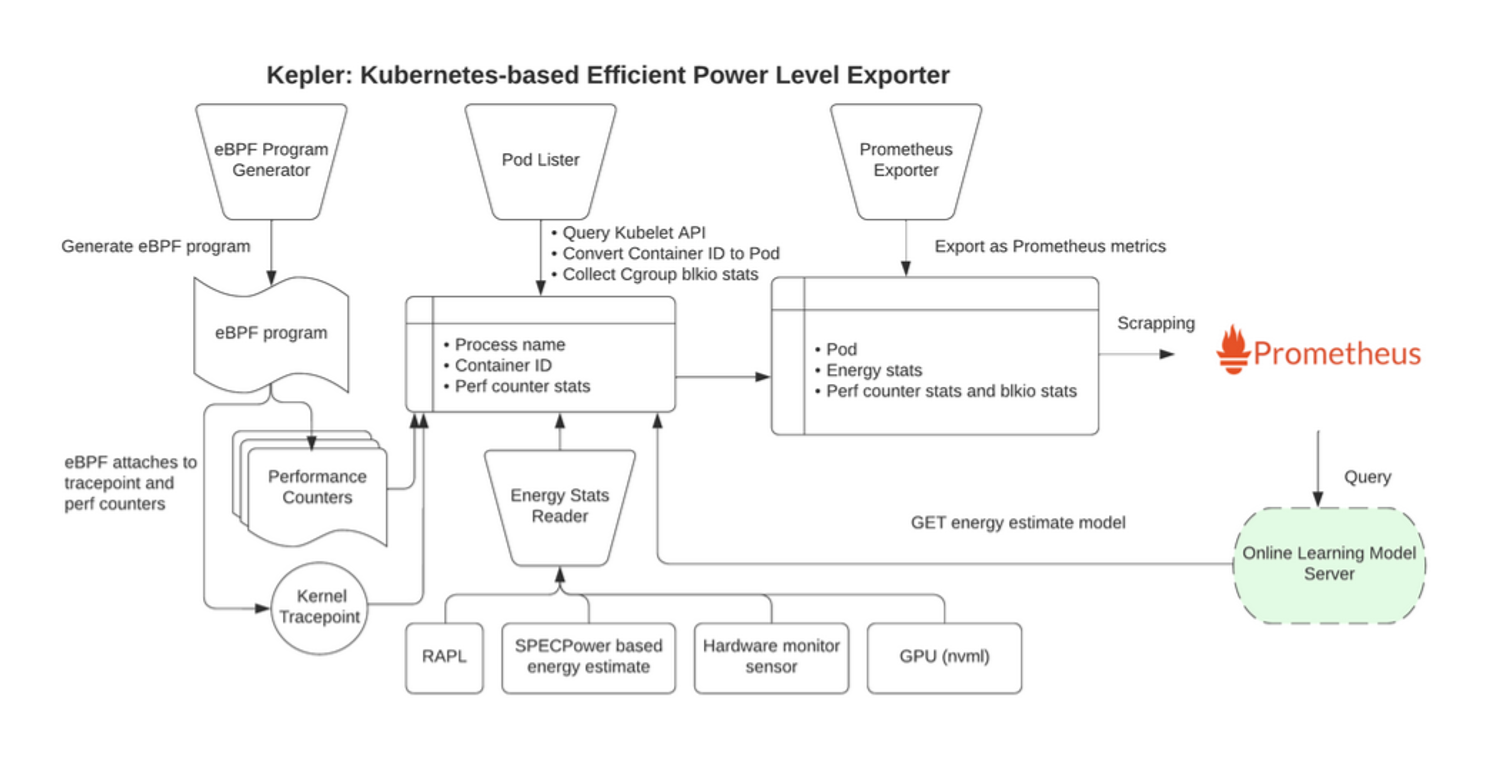
For bare-metal environments, Kepler employs CPU performance counters, monitoring aspects like CPU cycles, instructions, and cache misses. It also utilizes RAPL to provide energy readings. Furthermore, it employs a usage-based ratio method, attributing energy consumption to processes based on the percentage of total CPU instructions consumed.
In virtual machine settings where RAPL access is unavailable, Kepler adopts a machine learning prediction approach. It employs ML models along with BPF context switch events and stats to predict energy consumption at the container level. These techniques form the core of Kepler’s methodology, ensuring precise and efficient power consumption estimations across different infrastructures.
Smart Scheduling with AI
In the current experimental setup, we demonstrated a Kubernetes cluster with three nodes: one master node and two worker nodes. All nodes were equipped with Kepler and Istio deployments. The master node additionally hosted the load generation application and smart scheduling logic. Within the worker nodes, data storage services and business logic services were deployed to different nodes based on varying scheduling policies.
Regarding the testing environment, all three nodes had identical configurations: 8 cores and 32 GB of RAM. The software stack was based on Ubuntu 22.04 and included Kubernetes, DBS, Nginx, Istio, Kepler, and Wrk. We conducted tests with different workloads, ranging from 2 to 128 threads and corresponding increments in connection numbers (multiplied by 10). Input data varied from 2000 to 10,000. Each test lasted for 60 seconds.
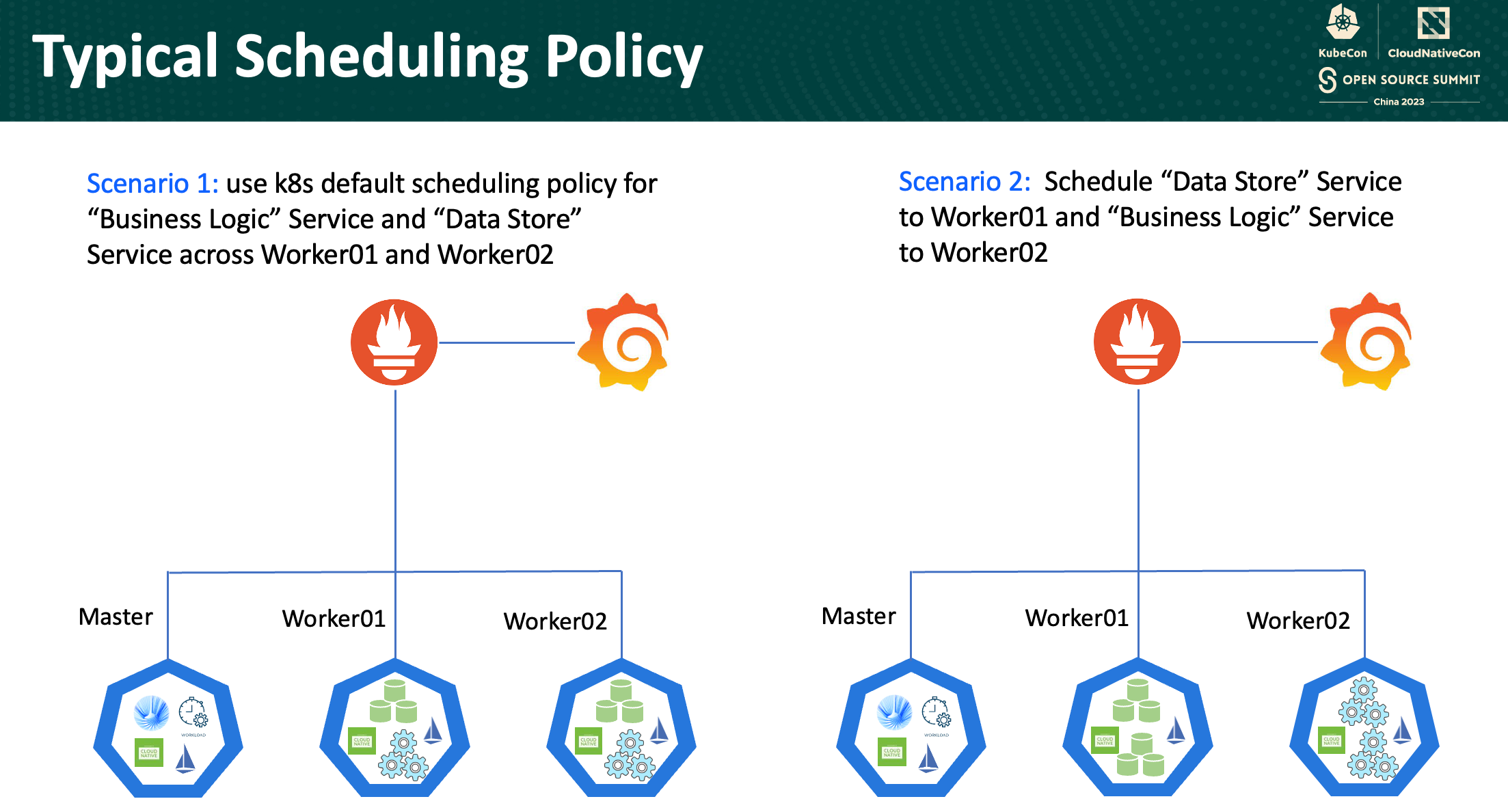
Scenario 1: Default Scheduling Policy
In the first scenario, we employ Kubernetes’ default scheduling policy, allowing the platform’s innate intelligence to allocate resources. The “Business Logic” Service and the “Data Store” Service are distributed across Worker01 and Worker02 based on Kubernetes’ default algorithm. This scenario relies on Kubernetes’ understanding of workload demands, node capacities, and resource availability. The approach embodies simplicity, leveraging Kubernetes’ built-in logic to ensure a balanced distribution of services. However, while default scheduling is convenient, it may not always cater to specific workload nuances, potentially leading to suboptimal resource utilization and performance imbalances.
Scenario 2: Customized Service Allocation
In contrast, the second scenario adopts a more targeted approach. Here, the “Data Store” Service is strategically placed on Worker01, while the “Business Logic” Service finds its home on Worker02. This customization allows for meticulous resource allocation, aligning services with nodes that best suit their computational and memory needs.
In terms of performance, there were notable differences between the scenarios. In the default Kubernetes scenario, the P99 latency and transactions per second (TPS) were superior compared to the second scenario. However, when considering energy consumption, the graph displayed the energy consumption trends of all pods within the hotel-res namespace over time. Notably, the energy consumption between the two scenarios remained relatively similar.
Later on, Smart Scheduling with Reinforcement Learning is introduced: Firstly, it observes various metrics such as workloads, Istio and Kepler metrics, CPU usage, and memory utilization. Based on this information, it devises scheduling policies for pods across different nodes, adjusting configurations accordingly. These decisions are guided by performance and energy consumption evaluations, forming the basis of rewards received by the system.
In the Kubernetes cluster environment, Smart Scheduling executes by scheduling pods onto nodes as recommended by its policies. To assess its performance, an evaluation method is employed, generating corresponding rewards. The process involves key steps in reinforcement learning. The state, denoted as S, signifies the agent’s current position within the Kubernetes cluster. Actions (A) represent decisions made by Smart Scheduling, including pod scheduling and scaling. Each action yields a reward, determined by sustainability, performance, and other factors, weighted accordingly (c_sus, c_perf, c_res, w_sus, w_perf, w_res). Episodes conclude when the agent reaches a terminating state, unable to take further actions.
Temporal Difference, a specific formula, calculates the Q-Value, gauging the effectiveness of an action (A) taken at a given state (S). This value, denoted as Q(A, S), is iteratively updated using the Bellman equation and temporal differences. The objective is to minimize state transfer costs, optimizing Smart Scheduling’s decisions within the Kubernetes cluster.
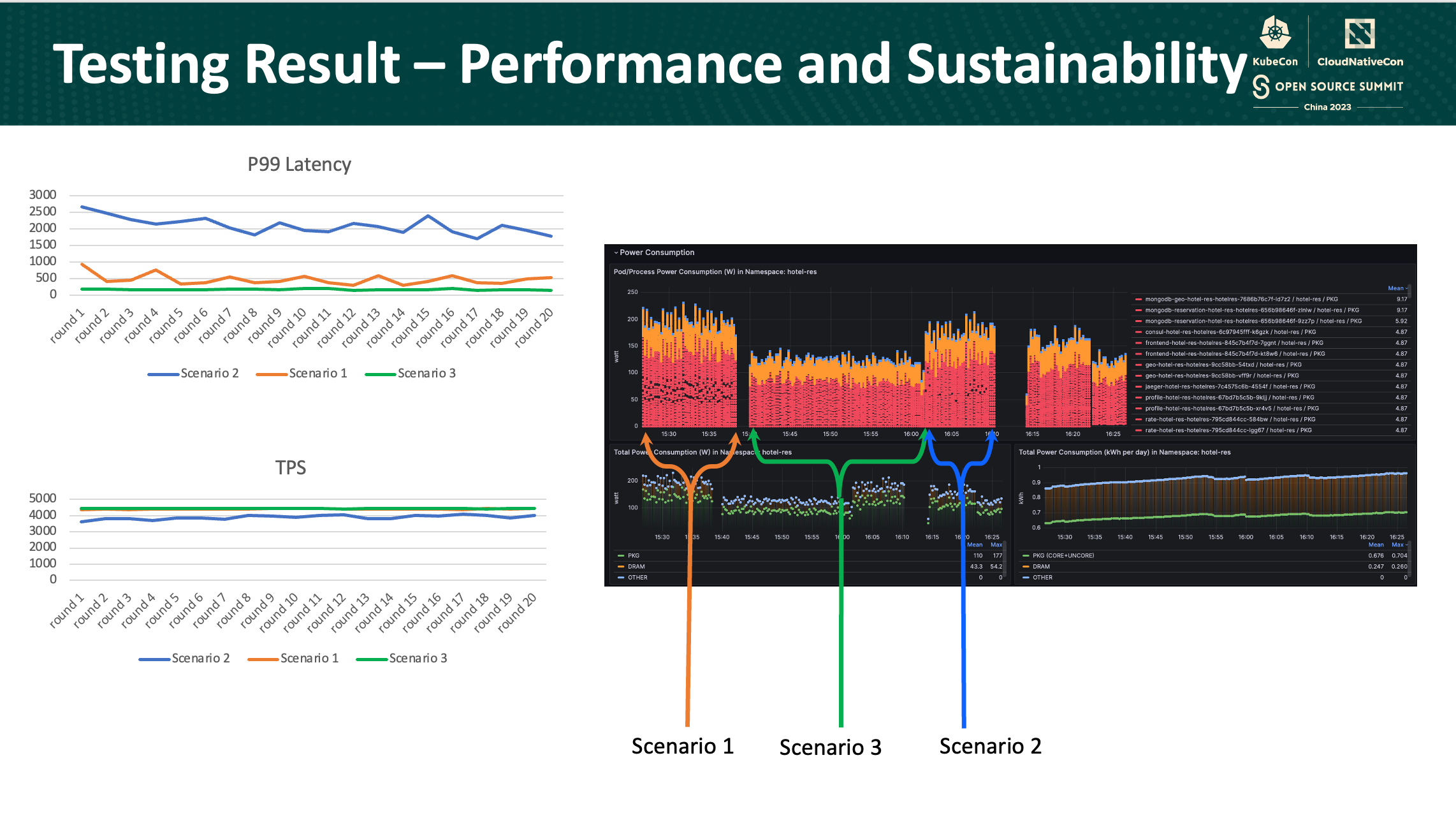
Through our analysis, we have identified an optimized scheduling approach. In Scenario 3, the strategy involves scheduling the database service on a single node while relying on Kubernetes’ default scheduling for the Business Logic service. This configuration outperformed both Scenario 1 and Scenario 2. This means that by dedicating one node specifically for the database service and utilizing Kubernetes’ default settings for Business Logic, the overall system performance ans sustainability were significantly improved.
Conclusion
The network metrics gathered by Istio are pivotal for optimizing Kubernetes scheduling. Kepler plays a key role by measuring power consumption at the container level, optimizing microservices in Kubernetes. Artificial intelligence, in synergy with Istio, Kepler, and smart scheduling, boosts microservices management through smart decision-making and real-time automation. Finally, Kepler’s energy consumption data and performance tests validate the effectiveness of these optimizations.