Hacia Microservicios con un rendimiento y sostenibilidad optimizados usando Istio, Kepler y Smart Scheduling
Publicación invitada como parte de cloud native sustainability week*
KubeCon + CloudNativeCon + Open Source Summit China 2023 fue llevada a cabo en Shanghai del 26 al 28 de septiembre, llamando la atención de los asistentes, temas relacionados con la sostenibilidad. Una charla notable durante el evento dió a conocer este tema importante. Abajo, recapitulamos esta charla sobre sostenibilidad ambiental en la conferencia.
Problema, Retos y Soluciones
En el panorama de la orquestación de microservicios, surgen retos que demandan soluciones precisas. La naturaleza distribuida heredada de los microservicios los lleva a incrementar el consumo de recursos y a tener costos de infraestructura más elevados. La asignación eficiente de recursos mientras se garantiza la escalabilidad se vuelve una preocupación apremiante. La interación de servicios introduce latencia, afectando el rendimiento en general. La Latencia y la interacción de servicios presenta problemas complejos, exigiendo optimización de las vías de comunicación entre las aplicaciones de microservicios. Además, la rápida proliferación de microservicios trae preocupaciones ambientales, específicamente a razón del consumo de energía y la huella de carbono. Encontrar un balance entre el rendimiento y la responsabilidad ambiental es crucial.
Para abordar estos retos, varias soluciones clave entran al juego. Los microservicios forman el marco de trabajo fundacional, mejorando la escalabilidad y flexibilidad dentro de las aplicaciones. Istio, una plataforma de malla de servios open-source, se asegura de una comunicación fluida y de la mitigación de la latencia a través del manejo de la orquestación del tráfico y la observabilidad. Kepler analiza el rendimiento de la CPU y los puntos de seguimiento del kernel, arrojando luz sobre la dinámica de energía y guiando a los arquitectos hacia prácticas de eficiencia energética. Kubernetes Scheduling asigna recursos, asegurando uso oótimo y previniendo desperdicio. Inteligenica Artificial (AI) se integra sin problemas con Istio, Kepler y Smart Scheduling, mejorando el manejo de microservicios a través de una toma de decisiones inteligente, monitoreo en tiempo real y asignación de recursos adaptativa.
Estas herramientas actuán como habilitadores estrategicos, transformando retos en soluciones prácticas, orquestando un futuro en el que los microservicios vibran al compás de la innovación, eficiencia y la consiciencia ambiental.
Istio y Microservicios
Istio se posiciona como una solución transformativa, extendiendo las capacidades de Kubernetes para crear una red programable y consciente de las aplicaciones. Aprovechando la robustez de Envoy como un proxy de servicios, Istio orquesta de manera harmoniosa la integracion entre Kubernetes y las cargas de trabajo tradicionales. Esta integración genera herramientas estandarizadas y universales para el manejo del trafico, telemetría y seguridad, lo que eleva las complejidades de las implementaciones.
Una de las fortalezas más notables de Istio yace en la habilidad de generar métricas de servicios integrales, ofreciendo conocimiento más profundo de la interacción de los microservicios. Estas métricas cubren aspectos cruciales como la latencia, los patrones de tráfico, errores y la saturación de servicios. Lo cual provee a los arquitectos una visión clara y en tiempo real de su ecosistema de microservicios.
Hecho a la medida para tráfico HTTP, HTTP/2 y GRPC, las métricas ofrecen un entendimiento granular de las dinámicas de la comunicación dentro de los microservicios. Por medio del monitoreo de parametros clave, Istio empodera a arquitectos y desarrolladores para optimizar sus aplicaciones efectivamente, asegurando rendimiento y fiabilidad continuo en el siempre cambiante entorno de las arquitecturas de software.
Nuestro enfoque principal está los servicios end-to-end de reserva de hotel, una parte esencial de la suite open-source de benchmark de DeathStarBench. Desarrollado de una manera sencilla usando técnicas cloud-native moderna, este servicio simula una carga de microservicios típica, especificamente para un sistema de reservas de un hotel. Está escrito en el eficiente lenguaje de programación Go (golang) y utiliza gRPC-go para comunicación entre microservicios. Este servicio es instrumental en nuestro estudio, permitiendonos explorar diferentes escenarios de planificación de recursos de una manera práctica y accessible, haciendolo una elección ideal para nuestro análisis.
Kepler y Modelado de Consumo
Kepler, conocido en inglés como “Kubernetes-based Efficient Power Level Exporter” (Exportador de niveles de potencia eficiente basado en Kubernetes en español), opera utilizando la tecnología eBPF para examinar el rendimiento de los CPUs y los puntos de seguimiento del Kernel. Estos datos recopilados, incluyendo información de los eventos de cambio de contexto BPF y sysfs, son introducidos dentro de un modelo de machine learning. Este proceso nos permite hacer estimaciones de consumo de potencia de los Pods de Kubernetes. Desde su creación, Kepler se adhiere a tres principios fundamentales: Es diseñado para ser universal, capaz de correr en varias plataformas como bare-metal o máquinas virtuales, admitiendo diferentes arquitecturas como x86, ARM o S390. Adicionalmente, es ligero, asegurando bajo impacto y bajos costos, y es está bien cimentado con investigaciones científicas, apoyandose de principios bien estudiados.
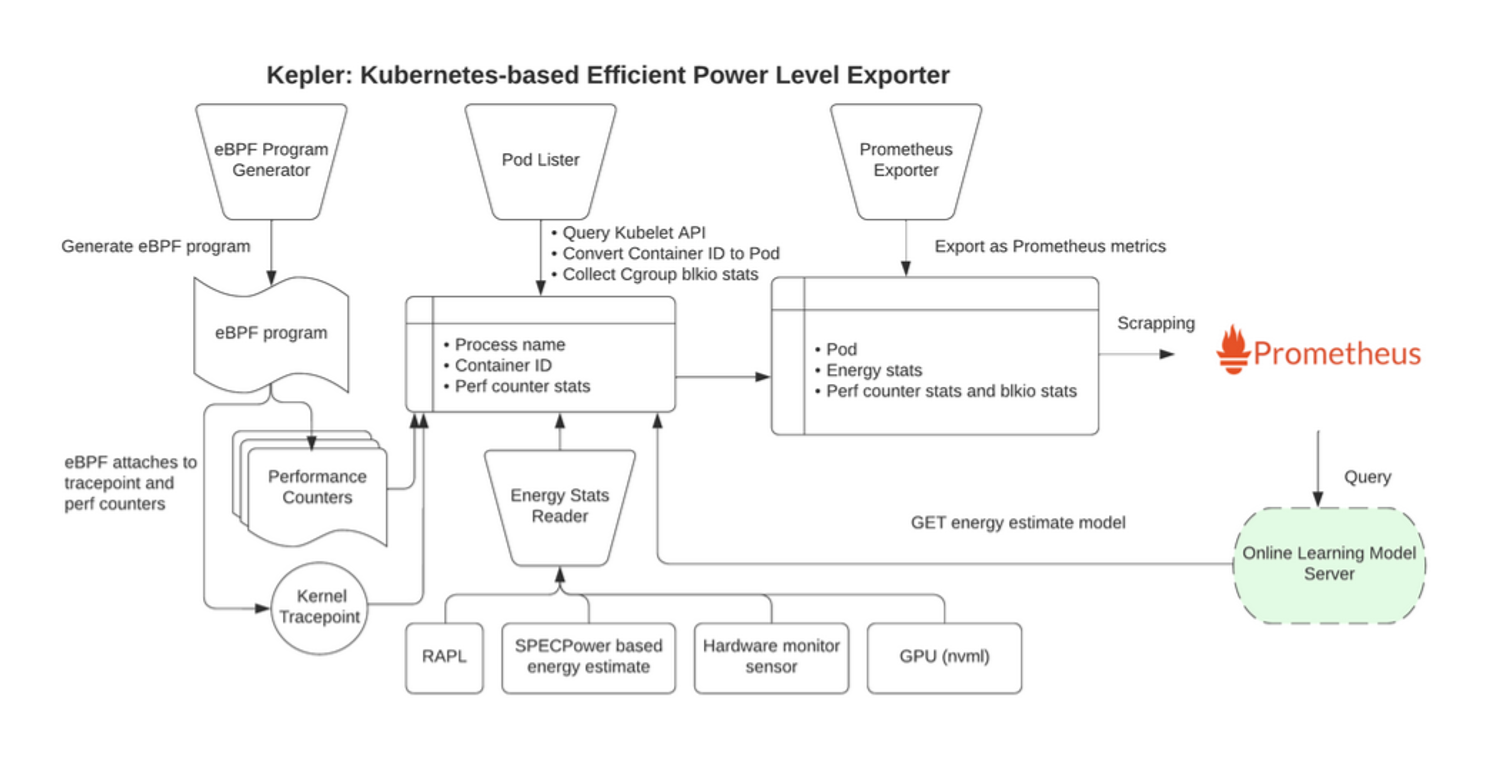
Para entornos bare-metal, Kepler emplea contadores de rendimiento de CPU, monitoreo de aspectos como ciclos de CPU, instrucciones y errores de caché. También utiliza RAPL para proveer lecturas de energía. Además, emplea un método de proporción basado en el uso, atribuyendo consumo de energía a procesos basados en el porcentaje total de instrucciones de CPU consumidas.
En configuraciones de máquinas virtuales donde el acceso de RAPL no está disponible, Kepler adopta un enfoque de predicción de Machine Learning. Implementa modelos de ML en conjunto con los eventos de cambio de contexto BPF y estadísticas para predecir consumo de energía a nivel de contenedor. Estas técnicas forman el núcleo de la metodología usada por Kepler, asegurando estimaciones de consumo de energía precisas y eficientes.
Smart Scheduling con IA
En la configuración del experimento actual, se usa un cluster de Kubernetes con tres nodos: un master node y dos worker nodes. Todos los nodos fueron equipados con deployments de Istio y Kepler. El master node adicionalmente corre una lógica para generación de carga y otra lógica para asignación de recursos inteligente. Dentro de los worker nodes, servicios orientados al almacenamiento de la información y servicios de la lógica del negocio fueron desplegados a diferentes nodos variando las políticas de asignación de recursos.
En relación al ambiente de pruebas, todos los nodos tuvieron configuraciones identicas: 8 núcleos y 32 GB de RAM. El stack de software usó Ubuntu 22.04 e incluyó Kubernetes, DBS, Nginx, Istio, Kepler y Wrk. Las pruebas fueron conducidas con diferentes cargas de trabajo, que van de 2 a 128 threads y los incrementos correspondientes en el número de conexiones (multiplicados por 10). Los datos de entrada variaron de 2000 a 1000. Cada prueba duró 60 segundos.
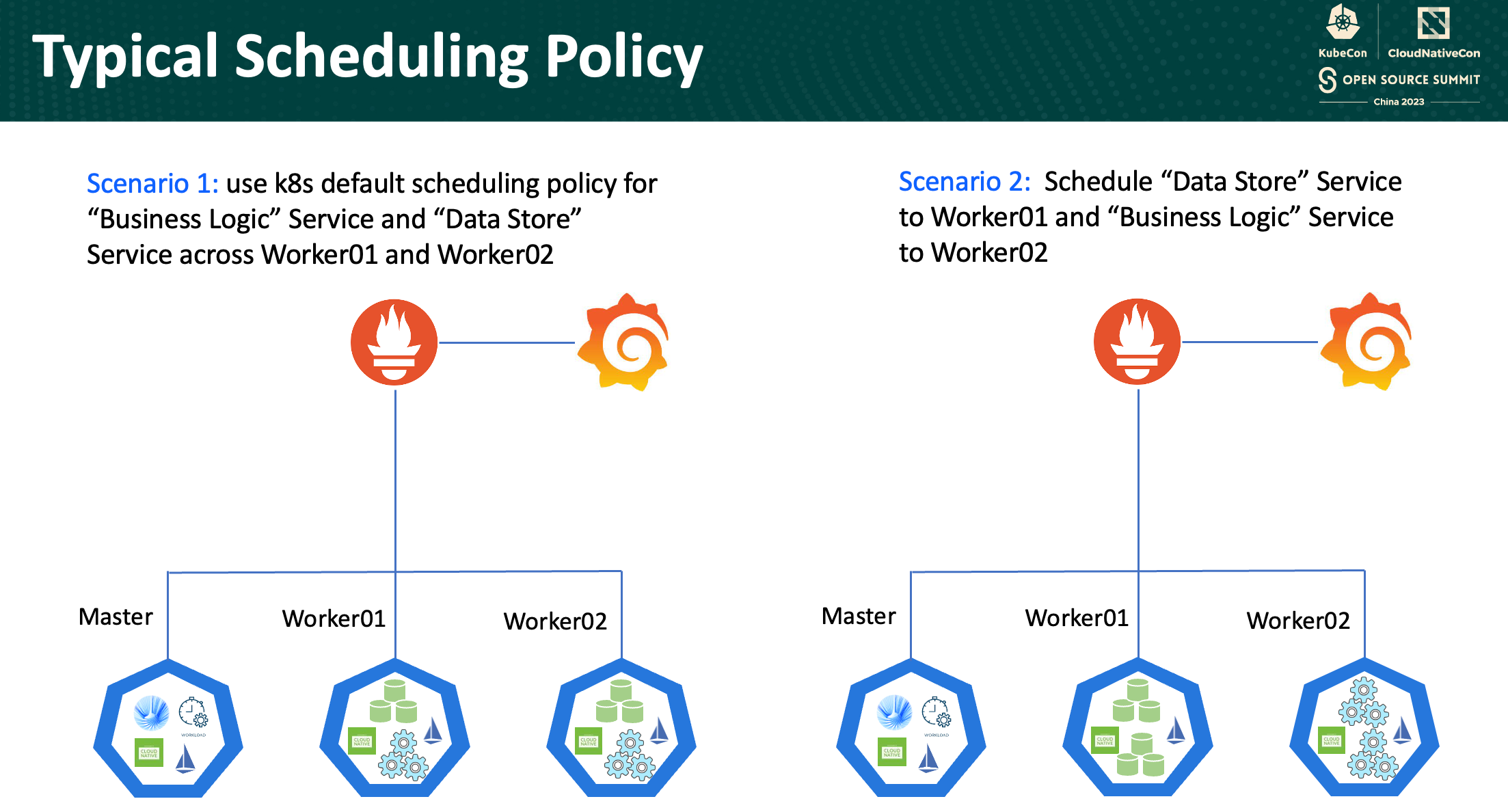
Primer Escenario: Política de asignación de recursos por defecto
En el primer escenario, se empleó la política de asignación de recursos de Kubernetes, permitiendo que la inteligencia innata de la plataforma asigne recursos. El servicio de “Lógica de Negocio” y de “Almacenamiento de Información” son distribuidos entre el nodo Worker01 y el nodo Worker2 conforme al algoritmo por defecto de Kubernetes. Este escenario depende de la capacidad de Kubernetes para entender la demanda de las cargas de trabajo, las capacidades de los nodos y la disponibilidad de recursos. Este enfoque representa simpleza, apalancandose de la lógica incorporada de Kubernetes que asegura una distribución balanceada de los servicios. Sin embargo, mientras esta estrategia de asignación es conveniente, puede que no siempre atienda las necesidades especificas de las cargas de trabajo, lo que podría llevar a una utilización poco óptima de los recursos y un desequilibrio del rendimiento.
Segundo Escenario: Asignaciónd de recursos personalizada
En contraste, el segundo escenario adopta un enfoque más dirigido. En este, los servicios relacionados con “Almacenamiento de Información” son posicionados de manera estratégica, mientras que los servicios orientados a la “Lógica de Negocio” encuentran su hogar en el nodo Worker02. Esta personalización permite una distribución de recursos más metículosa, alineando los servicios con los nodos que mejor convengan a sus necesidades computacionales y de memoria.
En términos de rendimiento, hubieron diferencias notables entre los escenarios. En el escenario que empleó la política de Kubernetes, el percentil 99 de latencia y transacciones por segundo (TPS) fueron superiores comparados con el segundo escenario. No obstante, cuando se considera el consumo de energía, el gráfico muestra las tendencias de consumo de energía dentro del namespace hotel-res a lo largo del tiempo. En particular, el consumo de energía entre los dos escenarios se mantuvo relativamente similar.
Más tarde, la estrategia de asignación de recursos con aprendizaje por refuerzo (Reinforcement learning) fue introducido: Primero, se observa varias métricas como las cargas de trabajo, métricas de Istio y Kepler, uso de CPU y utilización de memoria. Basandose en esta información diseña políticas de asignación para pods en diferentes nodos, ajustando la configuración debidamente. Estas decisiones son guiadas por medio de la evaluación de rendimiento y consumo de energía, formando las bases de las recompensas recibidads por el sistema.
En el entorno del clúster de Kubernetes, Smart Scheduling opera asignando pods a nodos tal como sus políticas lo dictan. Para evaluar su rendimiento, un método de evaluación es empleado, generando recompensas. El proceso involucra pasos clave de aprendizaje por refuerzo. El estado, indicado como S, representa la posición actual del agente dentro del cluster de Kubernetes. Las acciones (A) representa las decisiones hechas por Smart Scheduling, incluyendo asignación de pods y escalamiento. Cada acción produce una recompensa, determinada por sostenibilidad, rendimiento y otros factores ponderados correspondientemente (c_sus, c_perf, c_res, w_sus, w_perf, w_res). Los episodios concluyen cuando el agente llega a un estado terminal, incapaz de realizar más acciones.
La diferencia temporal, una fórmula específica, calcula el valor Q, midiendo la efectividad de una acción (A) tomada en un estado dado (S). Este valor, denotado como Q(A,S), se actualiza de manera iterativa usando la ecuación de Bellman y diferencias temporales. El objetivo es minimizar el costo de transferencia de estado, optimizando la toma de decisiones del Smart Scheduling dentro del cluster de Kubernetes
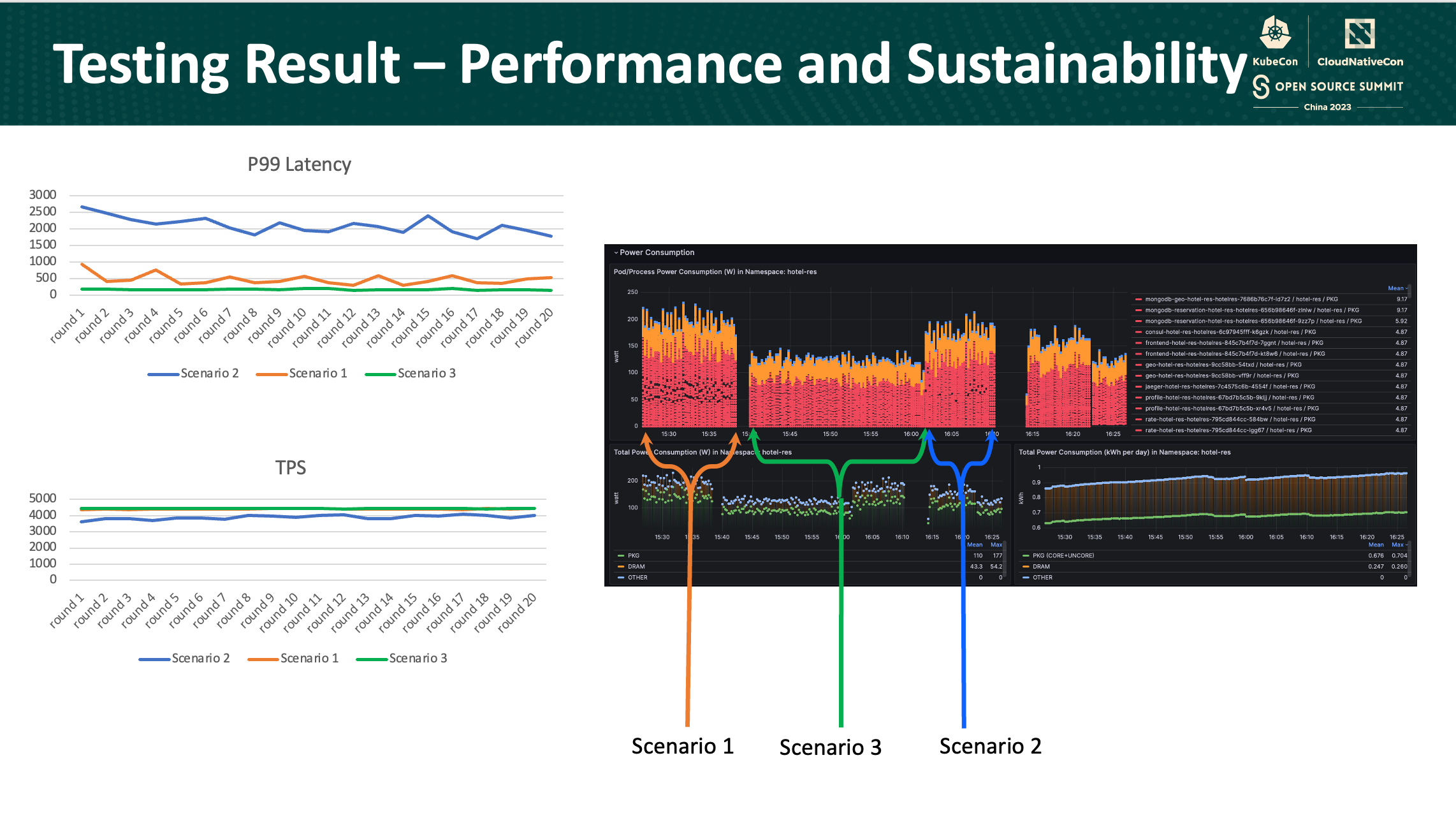
A través del análisis, hemos identificado un enfoque de asignación optimizada. En el tercer escenario, la estrategia involucra asignar el servicio de base de datos en un solo nodo mientras que se confía en la capacidad de asignación por defecto de Kubernetes para el servicio de “Lógica del Negocio”. Esta configuración tuvo un mejor rendimiento que el primer escenario y segunod escenario. Esto significa que cuando se dedica uno nodo específicamente para el servicio de base de datos y utilizando la configuración por defecto de Kubernetes para la “Lógica del Negocio”, el rendimiento general del sistema y sostenibilidad fueron mejoradas significativamente.
Conclusión
Las métricas recolectadas por Istio son fundamentales para la optimización de asignación de cargas de trabajo de Kubernetes. Kepler juega un rol importante en la medición de consumo de energía a nivel de contenedor, optimizando microservicios en Kubernetes. La Inteligencia Artificail, en sinería con Istio, Kepler y la asignación inteligente de cargas de trabajo, impulsa el manejo de microservicios mediante una toma de decisión inteligente y automatización en tiempo real. Finalmente, la información de consumo de energía de Kepler y las pruebas de rendimento validaron la validez de estas optimizaciones.