El camino hacia Scaphandre v1.0 - Desafíos y mejoras por venir en la evaluación del consumo de energía de TI
Publicación de invitado de la comunidad como parte de la semana de sostenibilidad Cloud Native
Esta publicación de blog trata sobre compartir los pensamientos y conocimientos que obtuvimos durante el desarrollo de Scaphandre con nuestros colaboradores, discutir con investigadores y profesionales de TI las formas disponibles actualmente para evaluar el consumo energético de un servidor IT y los límites de cada uno. A partir de esto tratamos de imaginar algunos de los desafíos que tenemos por delante y las pistas que identificamos para trabajar con ellos.
Evaluación del estado de consumo de energía del servidor de TI
¿Cuál es la participación del consumo de energía final en los impactos ambientales de las tecnologías de la información y la comunicación (TIC)?
Lo primero es lo primero: esta publicación de blog no debe interpretarse como una solución de ningún tipo. No hay solución a lo que nos pasa, no en los términos que solemos usar y pensar. 6 de los 9 límites planetarios han sido superados, lo que básicamente significa que tenemos al menos 6 razones para pensar que la actividad actual de la humanidad en el planeta tiene el potencial de hacer que los humanos la habitabilidad en la tierra es incierta. Estas 6 razones son nuestros impactos en: cambio climático, acidificación de los océanos, flujos biogeoquímicos en el ciclo del nitrógeno (N) y el ciclo del fósforo (P), el agua dulce global uso, cambio del sistema terrestre, erosión de la integridad de la biosfera y contaminación química.
¿Cuál es el peso de las TIC en esos impactos? En cuanto a las emisiones de gases de efecto invernadero que provocan el cambio climático, se dice que pesarán entre 2,1 y 3,9% de las emisiones globales en 2020. Lo más importante es la tendencia, ya que las proyecciones hasta 2025 hablaban de entre el 6% y el 8% de las emisiones globales. Además, la TI contribuye a la presión sobre los recursos naturales, especialmente los recursos abióticos/mineros (que están relacionados con la contaminación química), el uso de agua dulce, etc. La fase de uso y el consumo de energía final asociado podrían ser la parte más importante de la huella de carbono de una servidor o un equipo de red, si la intensidad de carbono de la electricidad consumida es alta. Sin embargo, esto no es cierto para los dispositivos de usuario final o incluso para un servidor que funcionaría en una red eléctrica con bajas emisiones de carbono. En esos contextos, la fabricación representa la mayor parte del impacto (puedes jugar con los gráficos de Datavizta para tener una idea). Dicho esto, aquí sólo estamos hablando de impactos ambientales directos, o “efecto de primer orden”, efectos de “segundo” y “tercer” orden son una historia compleja que probablemente sea la parte oculta y más grande del iceberg.
Con esta introducción, mejores mediciones del consumo de energía de TI no son una solución, sino solo una parte de la investigación necesaria para mejorar nuestra comprensión de la presión que la TI tiene sobre las redes eléctricas y encontrar ideas sobre cómo reducirla. Está lejos de ser lo único que se puede hacer en TI. El consumo de electricidad (energía final) en la fase de uso de las TIC no es sólo una cuestión de impactos ambientales directos, sino también de presión ejercida sobre las redes eléctricas en momentos en que necesitamos trasladar usos basados en combustibles fósiles a usos basados en electricidad.
Un poco de historia, midiendo el consumo energético de los recursos TI
Durante años, la única forma de medir la energía utilizada por un servidor informático era conectarlo a un vatímetro, disponiendo así de un dispositivo físico dedicado a obtener la energía de la máquina. Las cosas mejoraron un poco en 1998 con la aparición de IPMI cuando obtuvimos una forma de evaluar la energía consumida por la máquina desde una interfaz web o una API. Las SmartPDU también fueron una buena mejora, ya que les permitió obtener esas métricas en herramientas de monitoreo, bases de datos de series temporales y paneles de informes.
Esas 2 formas comparten un problema común: solo obtenemos el consumo global de una máquina. ¿Cómo decidir qué acciones tomar para reducir la energía utilizada, más allá de cambios de hardware, configuración UEFI/BIOS y actualizaciones de firmware? ¿Cómo obtener métricas de las infraestructuras que serían útiles para los equipos de producto y desarrollo y, además, para todos los que no trabajan en el centro de datos? Otra pregunta que podríamos hacernos sería: ¿cómo sabemos la participación de cada componente en la potencia de la máquina? Aquí viene la evaluación de potencia basada en software.
Medios y ámbitos de evaluación
Comencemos con una descripción visual de las diferentes formas de evaluar el consumo de energía de los componentes de una máquina y el ámbito que cubren.
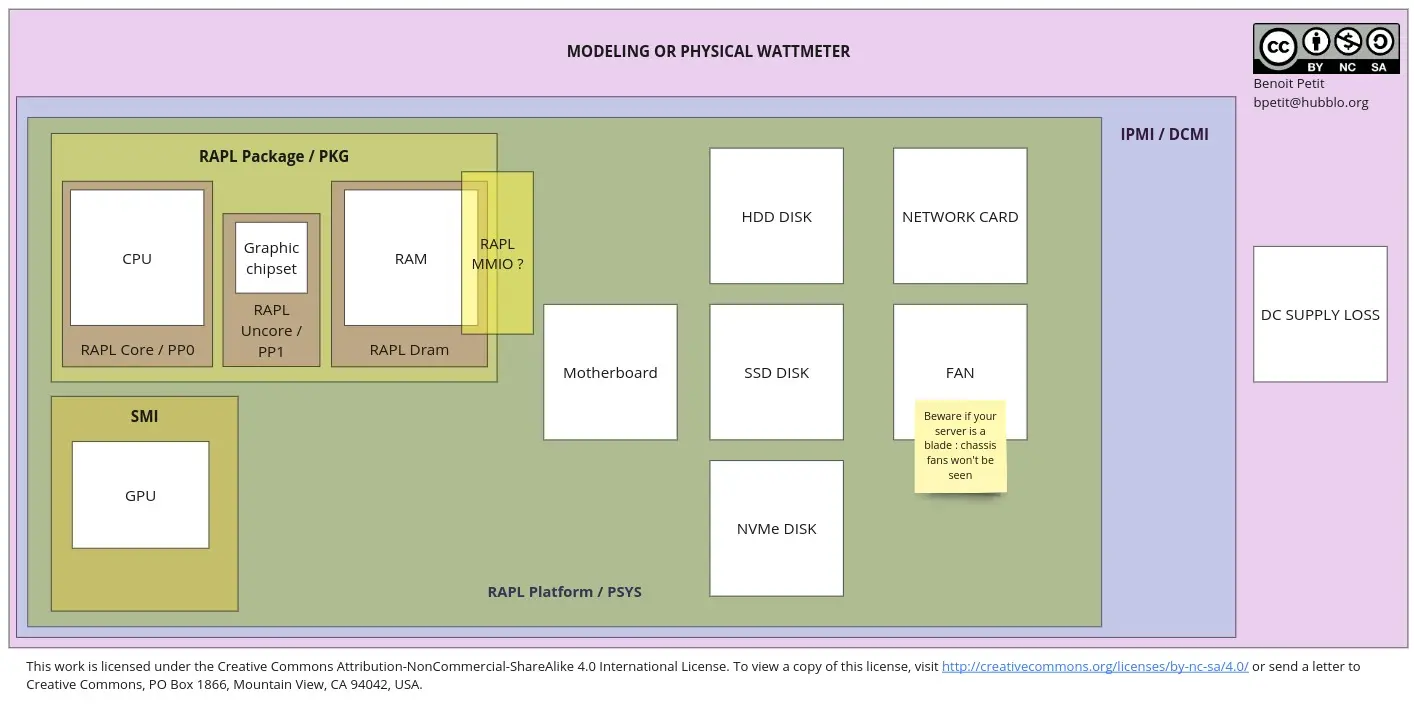 Un mapa de formas de evaluar el consumo de energía de un servidor y sus componentes.
Un mapa de formas de evaluar el consumo de energía de un servidor y sus componentes.
Es importante distinguir las métricas que provienen de sensores de bajo nivel proporcionados por los fabricantes de hardware o que provienen de un dispositivo dedicado a la medición como un vatímetro/PDU inteligente. A esas métricas las llamaremos “ascendentes” o “primarias”. Las métricas que realmente se generan a través de un modelo. Para ser claros, un modelo significa una fórmula o un algoritmo que especulará sobre las métricas reales en función de alguna información primaria a la que tiene acceso. A esas métricas las llamaremos “estimaciones” o “modelos”. Algunas herramientas de alto nivel/espacio de usuario proporcionan métricas tanto “primarias” como de “estimación”.
Para evaluar la energía consumida por un servidor completo, puede utilizar un modelo o un vatímetro físico/SmartPDU. La precisión de un modelo dependerá de muchos parámetros; como habrás adivinado, esto pertenece al ámbito de la estimación pura. Un vatímetro físico, o una SmartPDU, será (muy probablemente) muy preciso al proporcionar toda la potencia de la máquina. También será excelente para evaluar el consumo global de energía de una sala o rack de TI completo, tal vez de un grupo de máquinas que trabajan para el mismo servicio, pero no será útil para identificar qué componentes, aplicaciones o procesos son responsables del la mayor parte de este consumo, o aislar el consumo de un determinado servicio diferenciado del resto de servicios que se ejecutan en las máquinas.
Otra forma de evaluar la energía consumida por una máquina completa, en servidores de gama media a alta, son las tarjetas de administración compatibles con IPMI/ DCMI (se llaman IDRAC en Dell o ILO en HPE, por ejemplo). Esas tarjetas hacen que las métricas estén disponibles en la red, ya sea a través de una interfaz de usuario web, una API HTTP y, a veces, a través de una herramienta CLI accesible desde el sistema operativo del Host. Dependiendo de la implementación, es posible que tenga suficientes detalles para saber si la pérdida de suministro de CC se tiene en cuenta en la potencia “total” medida. Personalmente no pude encontrar ni crear una revisión de los métodos de evaluación de energía de las tarjetas de administración de los diferentes proveedores. A primera vista, parece que todos se basan en datos primarios, pero más pruebas parecen indicar que este no es el caso de todos los proveedores…
Profundizar más para obtener potencia por componente resultará un poco más complicado. Las CPU de arquitecturas x86 (x86_64), de Intel y AMD, construidas después de 2012 (más tarde para AMD), probablemente proporcionarán una función llamada RAPL, para el límite de potencia promedio en ejecución. Esta característica permite que los softwares del usuario establezcan límites de energía en la CPU, la RAM y la GPU integrada/empaquetada. Dado que permite la limitación de energía, permite el monitoreo de energía para esos componentes. Veremos en la sección dedicada que esto es cierto para la versión “histórica” de RAPL y el ámbito que cubre variará con las CPU más nuevas, en la sesión dedicada “una guía de supervivencia de RAPL”.
Las CPU ARM no ofrecen una función como RAPL hasta hace poco. Leí documentación que parece indicar que las placas ARM muy recientes tienen algo similar, pero aún no pude probar esta teoría. La potencia de las GPU de Nvidia se puede medir con nvidia SMI. Al momento de escribir este artículo, no conozco la función equivalente para las GPU AMD (pero si la conoce, ¡contácteme!).
Sesgos de evaluación de software y mejoras por venir
Si bien las herramientas de evaluación de software son una gran adición a la caja de herramientas de los profesionales de TI conscientes, ninguna de ellas es una solución perfecta que cubra todos los casos de uso. Sin duda, es necesario un enfoque combinado para tener una visión completa y precisa del uso de energía de una infraestructura.
Powercap es bueno, ¿no hay equivalente en Windows?
Tener acceso al sensor correcto es necesario, pero no suficiente. Lo hemos experimentado al crear soporte para Windows en Scaphandre. En GNU/Linux, tener acceso a las métricas RAPL desde el área de usuario es fácil, gracias al marco Powercap y al módulo del kernel. Hay métricas interesantes disponibles en la carpeta /sys/class/powercap, una carpeta por socket de CPU (paquete de CPU físico) que contiene la energía consumida por PKG, otra por dominio RAPL (Core, Uncore o Dram) para cada socket. En el caso de los dominios PSYS y MMIO, cuentan con una carpeta dedicada. Todo es un archivo, al estilo Unix, por lo que todo es simple.
En el mundo de Windows, cada solución que hemos encontrado que lee métricas RAPL (Intel Power Gadget y CPU-Z) tiene sus propios controladores. Es necesario tener un controlador en modo kernel (del cual nos abstraen powercap y sysfs, en el mundo Linux), ya que la instrucción __readmsr está en modo kernel, por lo que escribimos uno. Para que conste, MSR significa Registro específico del modelo, esos son los registros de la CPU que almacenan métricas RAPL.
Una vez que obtenga las métricas del controlador, también debe asegurarse de consultar esas métricas para el zócalo de CPU correcto; se requiere fijación del núcleo de la CPU si desea abordar máquinas de dos o cuatro sockets.
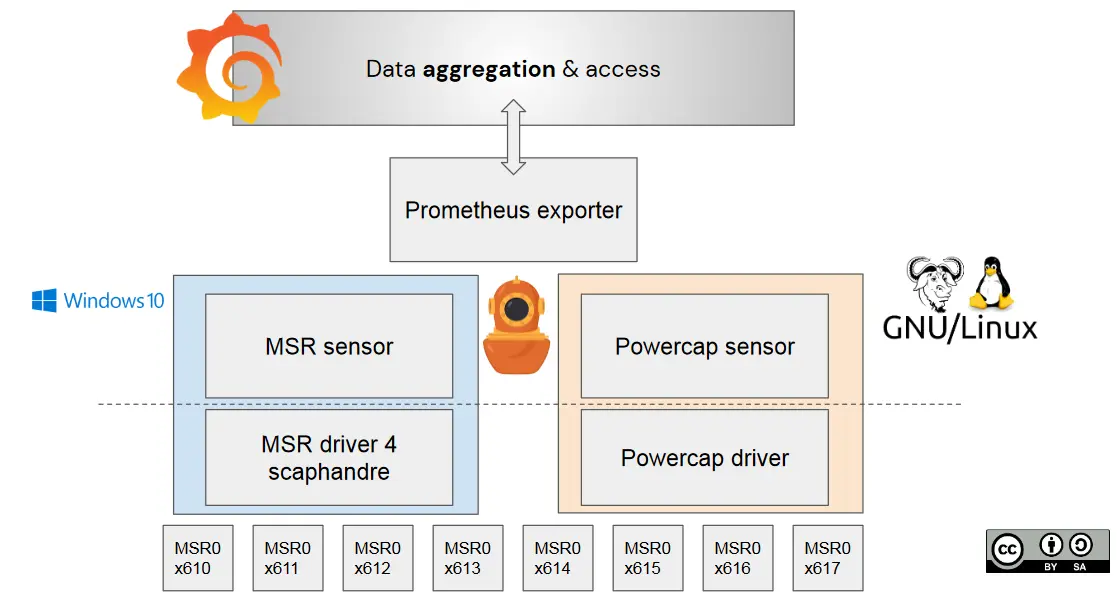
Comparación entre implementaciones GNU/Linux y Windows de Scaphandre
Una guía de supervivencia RAPL
Como es una interfaz utilizada por muchos programas de evaluación de energía, RAPL se hizo famoso en algunos círculos de TI y ESG. Me parece que a veces todavía se malinterpreta. La precisión de RAPL y el perímetro que cubre son dos temas diferentes.
Según mi revisión de la literatura, RAPL es exacto, a partir de su segunda generación (posterior a Broadwell), pero no cubre un perímetro completo. Como has visto en el esquema, “Paquete”, o “Pkg”, solo incluye la potencia de la CPU (Core), la Ram (DRAM) y la GPU integrada (Uncore). Comparar Pkg con una evaluación basada en IPMI/DCMI o SmartPDU probablemente sea decepcionante si se analiza la energía consumida en un período de tiempo decente. Se supone que son más cercanos cuando buscas momentos en los que la CPU está más activa, y más diferentes cuando la máquina está casi inactiva.
RAPL se vuelve un poco más completo con respecto a las mediciones de energía provenientes de su dominio PSYS (o “Plataforma”), que está disponible en las CPU posteriores a Skylake y proporciona energía a toda la placa base o System On Chip (y los componentes conectados), según a la documentación. Todavía estamos experimentando con esas métricas, ya que se implementarán en Scaphandre 1.0. Parte de nuestro trabajo futuro es documentar mejor su comportamiento, dependiendo del hardware disponible en la placa.
Como PSYS se refiere a máquinas bastante recientes, no es probable que sea una solución perfecta para una infraestructura completa. Además, tenga en cuenta que, a pesar de lo que suele decirse, normalmente no es una estrategia sostenible reemplazar los servidores de TI existentes por otros nuevos. Si bien las máquinas más nuevas podrían ser más eficientes energéticamente, el impacto de su fabricación (con respecto a las emisiones de GEI, el agotamiento de los recursos abióticos,…) ciertamente obstaculiza los “ahorros” del impacto esperado (esto es discutible según el contexto, la configuración exacta del hardware y la ubicación del servicio). ). En este sentido, darse cuenta de que las nuevas máquinas tienen mejores capacidades de medición podría tentar a uno a tener una infraestructura más moderna, le recomiendo encarecidamente que no haga tal cosa.
¿Qué pasa con el dominio MMIO? Esto parece estar relacionado con la actividad de entrada y salida de la memoria. Estamos experimentando con él estos días, lo pondremos a disposición (como una etiqueta específica) en Scaphandre 1.0 y esperamos documentarlo mejor en un futuro cercano.
Además, también puede descubrir que, dependiendo de la herramienta de usuario en la que confíe para obtener esas métricas, la forma en que se proporcionan esas métricas puede cambiar. También hay mucho que decir aquí, pero ese debería ser el tema de otra publicación de blog en hubblo.org. Para Scaphandre, ahora estamos alimentando una página de compatibilidad. Allí también puede encontrar información útil genérica relacionada con RAPL.
Por último, pero no menos importante, si bien el uso de métricas RAPL puede resultar enriquecedor, ya que tiene una visión bastante precisa del consumo de energía de los componentes de su máquina, hay un problema. Cabe decir que este perfil de consumo probablemente será muy específico de su hardware y configuración. El contexto de ejecución de un software o servicio determinado también es esencial si desea evaluar su consumo de energía. Dependiendo de su tiempo de ejecución, ya sea que se esté ejecutando de forma nativa, en una máquina virtual (la configuración del hipervisor también será importante entonces), o en un contenedor y dependiendo de los otros servicios que se ejecutan en el host físico y su comportamiento, la evaluación puede ser más o menos impactado. Además, de una máquina a otra, aunque el hardware sea el mismo, es posible que puedas echar un vistazo más de cerca (al menos): hyper threading, turbo boost, modo de eficiencia energética,…
Conclusión
Como habrás comprendido, estamos lejos de tener todo lo necesario para obtener una comprensión precisa y completa del consumo energético de un servidor y, por tanto, optimizar todo lo que podamos para reducirlo. Así que, ¿Qué podríamos hacer? ¿Cómo podríamos igualar la brecha entre métricas precisas de consumo de energía global provenientes de SmartPDU y evaluaciones más pequeñas e incompletas del uso de energía por componente o por proceso?
Como habrás adivinado, necesitaremos construir y utilizar modelos de estimación de potencia además de las mediciones de datos primarios. Incluso si los fabricantes proporcionan un conjunto cada vez más completo de sensores, no es probable que los equipos de TI más antiguos desaparezcan, y no creo que depender únicamente de la innovación de hardware sea la clave (se ha demostrado que no lo es).
El camino para obtener modelos más genéricos, completos pero lo suficientemente precisos para obtener la potencia de una máquina sin ningún dispositivo físico o sensor disponible se compone, hasta donde sabemos, primero de una mejor comprensión y documentación de las formas existentes de evaluar la potencia. En segundo lugar, necesitaremos datos detallados específicos del hardware para luego proporcionar modelos que permitan la evaluación de la potencia en contextos diferentes o más difíciles, incluidos, entre otros: IoT, hardware antiguo, IaaS de nube pública (este necesitará más trabajo complementario). ya iniciado en Boavizta.
Para obtener esas métricas, lo necesitamos. Necesitamos obtener más datos, de máquinas y configuraciones de hardware más diversas, ya sea ejecutando pruebas comparativas con ellas o recopilando esas métricas de la manera más pasiva posible mientras funcionan como de costumbre. Podrías ayudarnos con eso a través del proyecto Energizta.
Además de ayudarnos con el proyecto Energizta, no dudes en contactarnos sobre cualquier imprecisión o sugerencia que puedas encontrar relevante respecto a este post. Se trata de una construcción de conocimiento abierta y colaborativa. Sabemos que podemos entender mal las cosas, que esta es una presentación sesgada del tema, que hay mucho más por hacer y queremos hacerlo con cada persona que quiera ayudar.
biografía
Benoit Petit, cofundador de Hubblo, una empresa de consultoría y edición de código abierto para la evaluación y reducción de los impactos ambientales de las TIC. En este sentido, también mantengo Scaphandre, el agente de monitoreo de energía de código abierto descrito en esta publicación. También soy colaborador de Boavizta, una organización sin fines de lucro que fomenta la colaboración de organizaciones públicas y privadas a través de bienes comunes digitales, para hacer que las TIC sean compatibles con las fronteras planetarias.
Gracias
Me gustaría agradecer a Victorien Molle por su gran contribución al controlador de Windows en el que confía Scaphandre, a Guillaume Subiron por su increíble trabajo en Energizta, a la gran comunidad de contribuyentes de Scaphandre, a David Ekchajzer, Leonard Pahlke y Guillaume Subiron nuevamente por sus reseñas de este blog. correo.